
How to Build an ETL Process

The information must be accurate, up-to-date, fast and easily accessible. It’s not just a requirement, it’s the condition for performing high-quality analysis and making weighted business decisions. The bigger the company is, the more it’ll pay for the wrong decision. So work with data must be organized to produce the desired result. Among the many tools that can help you build an appropriate data workflow to possess reliable information, ETL acts as the missing piece of the puzzle.
In this article, we will look at the ETL concept, study the best ETL software development practices and tools, and show you how to create an ETL process step by step.
What is ETL
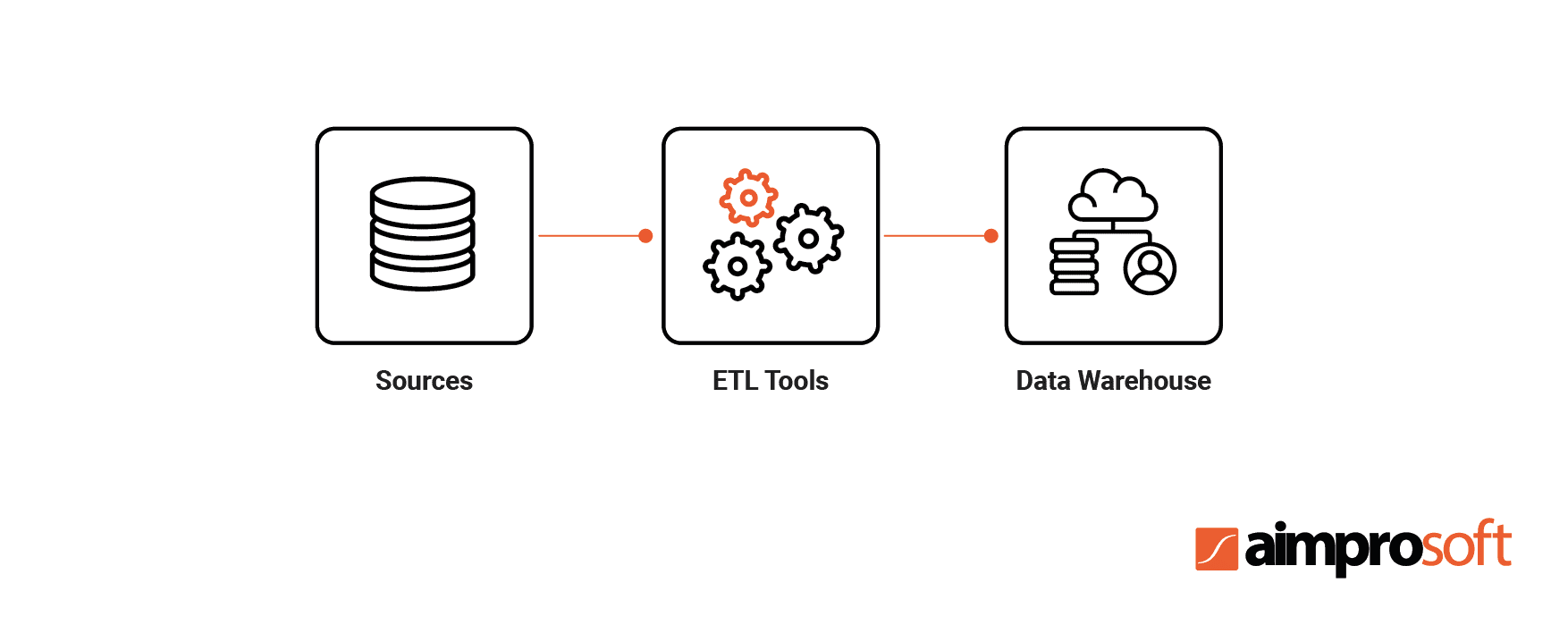
ETL is an automated data optimization process that converts data into a digestible format for efficient analysis. The traditional ETL process consists of 3 stages: extract, transform, load. Raw data is extracted from different source systems and loaded into the data warehouse (DWH) during transformation. As a result, ETL reduces the size of the data and improves the quality of its analysis.
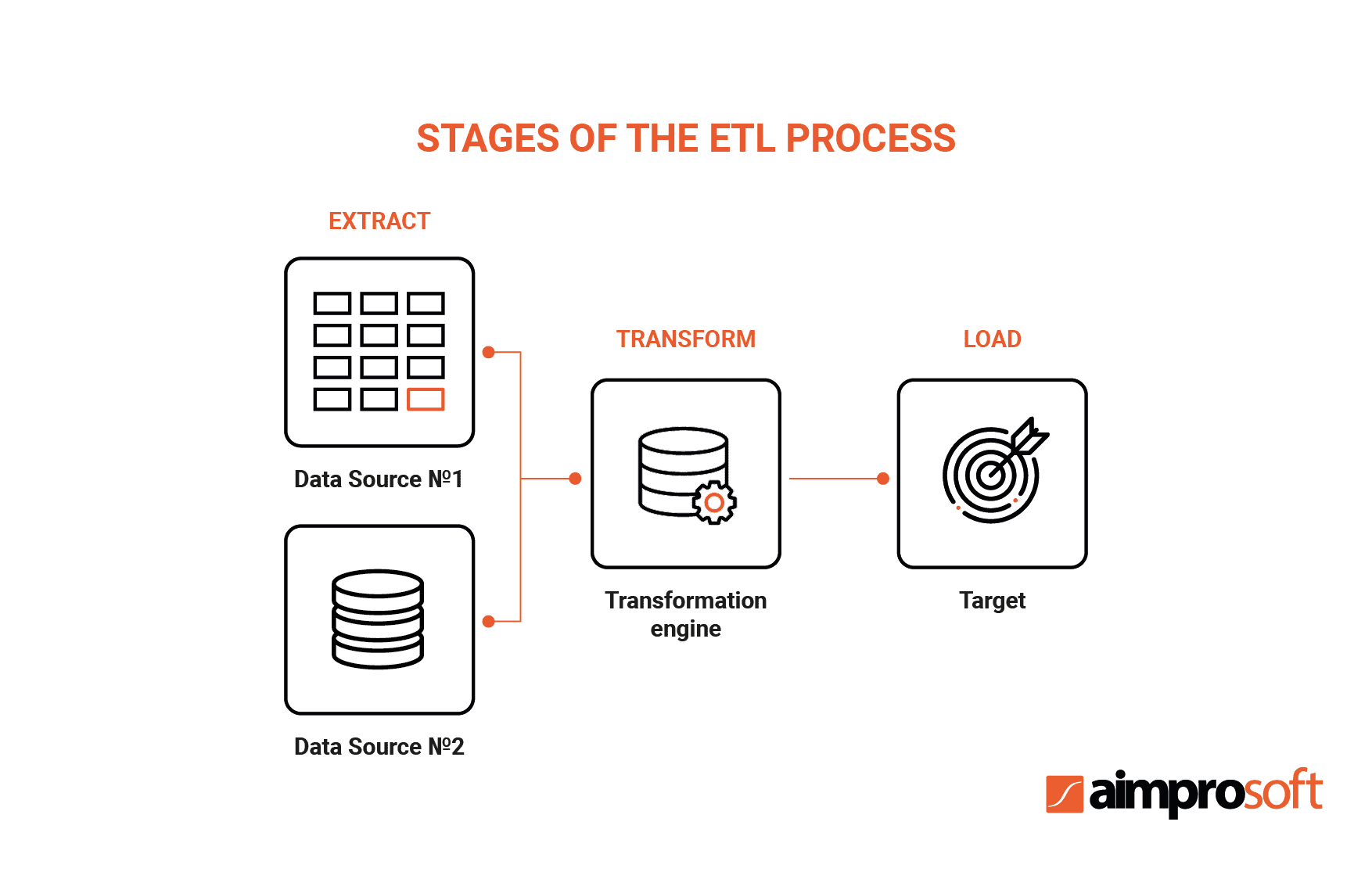
When building an ETL platform and infrastructure, you should first choose from which source to integrate data, then carefully plan and test its transformation. This process is known for its complexity and resource consumption, so why does your business need it?
Why do you need ETL
The necessity in ETL design and development has risen from the business need to obtain reliable reporting from the disjoined data storage systems of multiple company’s applications, such as ERP, PLM, CRM, MES, etc. These disconnected storages lead to such complexities as random errors in the code and data inconsistencies.
You may need to develop an ETL process because it offers an answer to a couple of fundamental business problems:
- It maintains an audit trail after data transformation to track details of information changes.
- Brings data to a single standard into one centralized place.
- As a result, large datasets are prepared for high-quality business analytics.
- Scanning and file recognition.
- You will get a global view that allows making better business decisions.
This is done through the following ETL functions:
- moving data from different sources to data warehouses;
- carrying out complex transformations with subsequent storage of data;
- providing automatic updates to data warehouse when information changes;
- preparation of data for analysis to improve business decisions.
Considering the valuable opportunities ETL processes provide working with data, the need for these solutions becomes obvious. But what is the ELT process, and how does ETL design and development differ from the ELT development life cycle?
ETL vs ELT
To assess what solution, ETL or ELT, suits best your business purposes, we need to understand how each of them works, plunge deeper into their peculiarities, and draw a clear comparison.
As we already mentioned above, the ETL process consists of 3 stages: extract, transform and load. It extracts raw data from different sources and puts it into a staging area, where the transformation takes place. Data is then loaded into the DWH where it is converted into meaningful information for further business analysis performed by business intelligence (BI) tools.
ETL uses traditional OLAP (online analytical processing) data cubes and relational database management systems (RDBMS). The staging area in ETL is located between the source and the target system, where the transformation occurs.
Such a process structure creates the following advantages:
- ETL allows achieving faster and more efficient information analysis thanks to data structuring;
- data is more qualitative, and access to it is easier because of the ETL toolkit, which simplifies the process of extracting, transforming and loading, as well as access to information;
- during the ETL process, you can adapt the data to the security protocols you need.
As for the disadvantages of ETL, we can highlight the following:
- the row-based approach can cause reduced performance;
- ETL may require additional hardware costs if you do not run it on a database server;
- traditional ETL processes do not have built-in mechanisms for finding and monitoring errors.
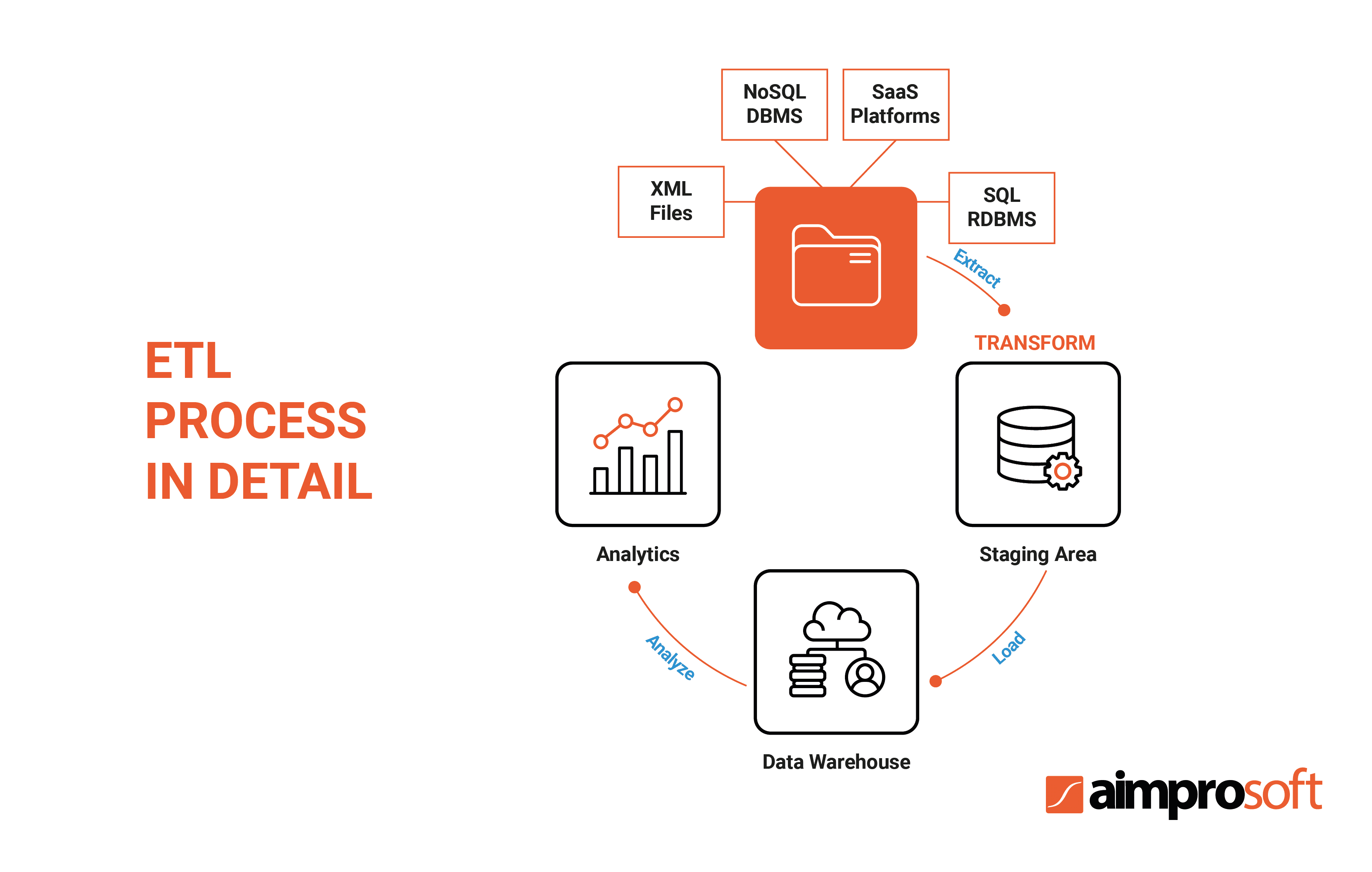
Unlike ETL, ELT processes change the order of transformation and loading, which allows for fast records movement. Data transformation in ELT takes place in the DWH, without the need for data staging. Since the ELT database engine performs the transformation, the data structuring is non-existent before accessing the data warehouse. So it results in slower and less efficient information analysis.
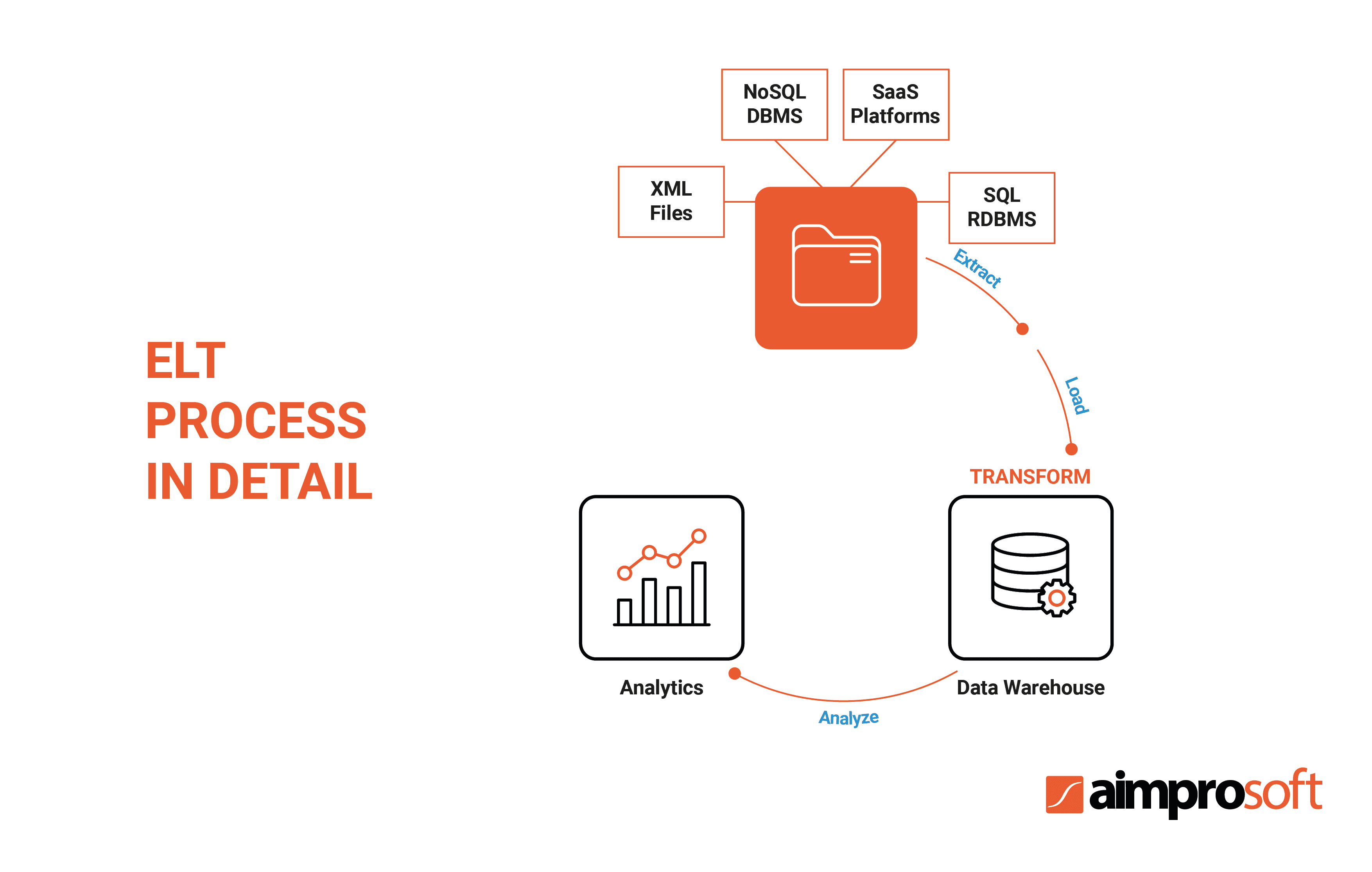
The ELT process consists of extract, load and transfer, in which data is passed through the DWH for necessary transformations, ignoring the preparation stage. ELT uses cloud-based data warehousing solutions for any data types: structured, semi-structured, unstructured, and raw ones.
This is stemmed from the fact that ELT directly interacts not with OLAP, but with data lakes — a special type of data store that accepts any data. The data lakes’ specificity is that you can instantly load raw data in any format. But it should be noted that the transformation stage is still necessary before its analysis.
All of the above forms a number of ELT process advantages:
- ELT is more beneficial when working with massive datasets and faster when loading data due to the lack of transformation between extract and load stages;
- because of interaction with high-efficiency data concepts such as data pipelines and cloud, a high level of information safety and performance is achieved;
- it requires less time and resources for transformation and loading stages, using parallel processing.
At the same time, these benefits are accompanied by the following disadvantages:
- tools that offer full support for ELT are quite limited;
- there is a lack of modularity due to set-based design for efficient performance, which results in a lack of functionality;
- since the ELT data warehouse lacks run-time monitoring statistics, you may face difficulties in tracking and analyzing information flow in a particular process.
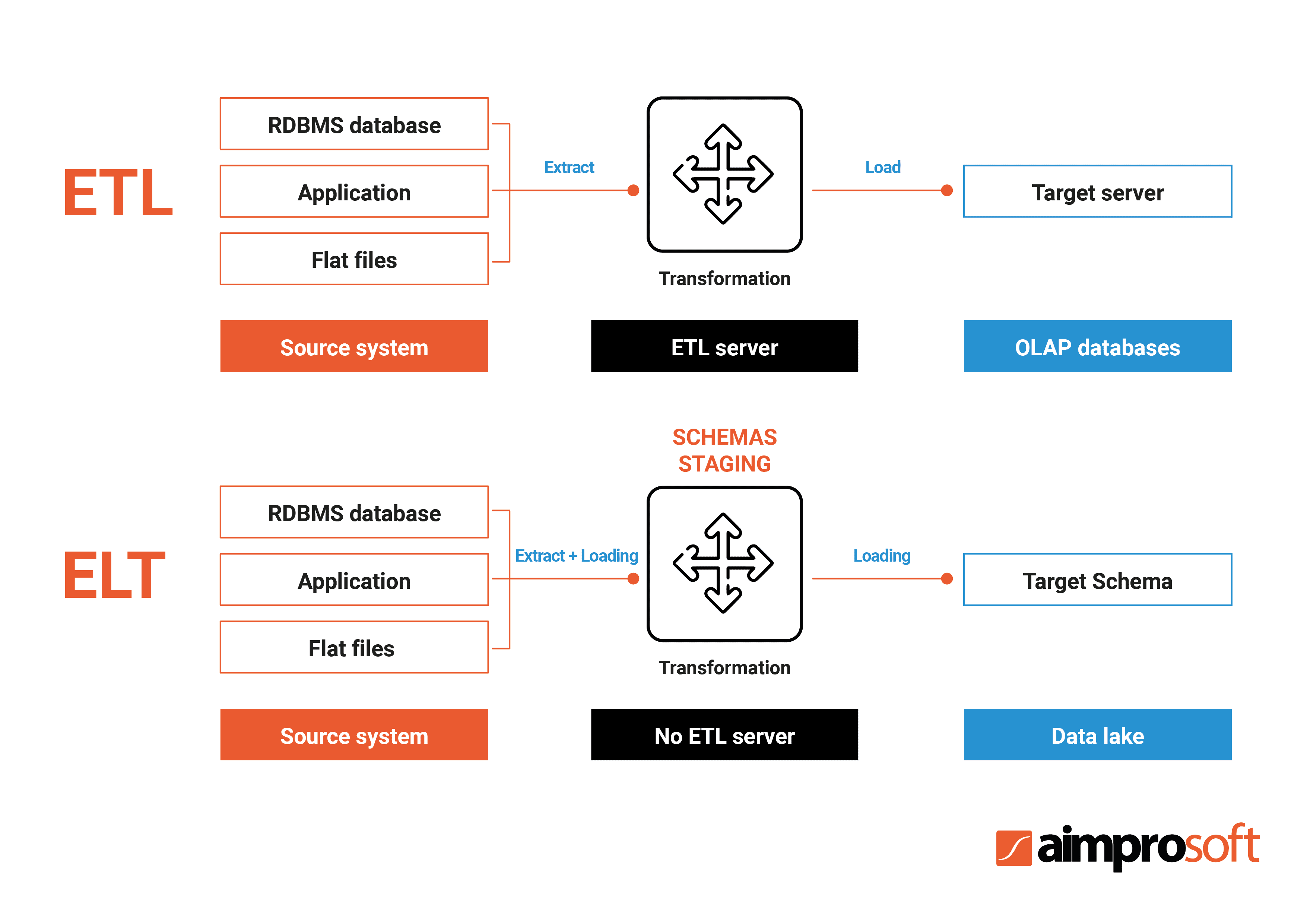
Let’s compare ETL and ELT to evaluate pros and cons of both data integration methods:
| Parameters | ETL | ELT |
|---|---|---|
| Data movement | Slow movement | High-speed movement |
| Data loading | Long process of loading | Quicker and smoother loading |
| Transformation | Transformation takes place in the staging area | Transformation takes place in the data system, without the need for a staging area |
| Analysis | Once the data is loaded, data analysis is faster, efficient and stable | Not the best option for fast data analysis |
| Security | More secure data way and compliance with HIPAA, GDPR, etc. | Has potential leaks and may be at risk of violating regulatory compliancу |
| Maintenance | High maintenance required | Low maintenance since data is always available |
| Tools and experts availability | The time-tested process with over 20 years in use. Availability of ETL specialists | Modern technology. More difficulties in finding high-skilled specialists |
So in what cases is it better to use ETL, and in which situations to choose ELT processes? Develop an ETL solution if data analysis efficiency is more important to you than its transformation and loading speed. Also, ETL provides better information privacy and compliance due to cleansing data before the loading.
ELT is the most modern way of dealing with data circulation, and it synergizes best with big data companies. However, it requires significant resources to maintain analytical cloud capacities. If you need to have all the information quickly in one place, there is nothing better than ELT yet.
As for the price of ETL and ELT, only a cloud solution can provide a cost indication, since it will require a certain monthly fee. Meanwhile, there is no definite answer when using a local server — the price will depend solely on the project’s specifics and your requirements.
Since it is very problematic to create ETL solutions from scratch, specifically designed development tools are usually used for helping with their building.
ETL development tools
The complexity of building an ETL platform from scratch depends on the variety of supported data processing and transformation algorithms. Enterprise is distinguished by supporting a lot of processing options, which takes a lot of time to write a high-quality ETL product. Thus it is worth using ready-made solutions to develop an ETL solution.
Then, you should choose between open-source and licensed tools. The license price may vary from several hundred to thousands of dollars per month. Needless to say, their quality is proportional to the price.
However, there are free open-source tools, which offer only part of the functionality of the licensed ones and require much more development effort. So we recommend making a decision based on the size of your company and overall feasibility. Ready-made solutions are rather expensive, and if you are short on resources, then it might make sense to write your own solution.
Finally, it should be noticed that without using development tools, the ETL development process will become much more complicated: your systems will downgrade in performance, user-friendliness, and professional support.
ETL frameworks, libraries and tools should be selected according to your project’s specificities since they rely on the business situation and the use case. Let’s take a look at its most prominent representatives:
Xplenty
One of the ETL tools market leaders in 2019, Xplenty is a cloud-based ETL platform that offers a simple and effective way to combine multiple data sources and build data pipelines between them.
Xplenty
MongoDB, MySQL, PostgreSQL, storages for Facebook and Jira products, plus more than a hundred SaaS sources are packaged with Xplenty. The creators of the product highlight scalability, security, and excellent customer support as its key advantages. In addition, the solution maintains compliance with HIPAA, GDPR, and CCDA. Xplenty did not disclose the price but offered a free trial for seven days as a demonstration version.
G2 score — 4.4 out of 5
Learn more about GDPR compliance finer points in our special article
Oracle
Oracle Data Integration (ODI) is a special environment for creating and managing data integration processes. ODI comes in two versions: on-premises and cloud. Unlike most ETL development tools, ODI also supports ELT workloads, as well as high-volume data and SOA (service-oriented architecture) enabled data services.
Among the disadvantages of ODI, we can single out the difficulty in learning and the need for training to work with it. ODI offers standard, enterprise, and government products. It has a flexible pricing model consisting of “Pay As You Go” and “Monthly Flex“ paid per hour plans.
Oracle
This platform is suitable for current Oracle users, since it is part of the Oracle ecosystem, as well as for companies that use ELT workloads.
G2 score — 4.0 out of 5
Informatica PowerCenter
Informatica PowerCenter is one of the enterprise cloud data management leaders, which is unconditionally confirmed by 500+ partners around the world and a billion-dollar revenue. The PowerCenter product is specially designed for data integration and is famous for its high performance and wide compatibility with different sources. The solution supports all possible data types and integration sources.
Morioh
As for the PowerCenter’s drawbacks it may be noted the high price and slow operation at high loads. Nevertheless, Informatica’s product is one of the most powerful on the market and is ideal for large enterprises with an appropriate budget.
G2 score — 4.3. out of 5
High-quality tools unleash their full potential while building an ETL platform only when you use the best practices at the development stage. Let’s get directly to their list.
Best practices
To provide the most efficient operation of your ETL process, you should follow the best practices gained from experience built up in this field. We have highlighted several methods that will certainly help you while working with ETL processes.
1. Reduce data input
The amount of data included in the ETL process determines the speed and quality of its processing. Therefore, try to get rid of unnecessary records before starting the ETL process. Then, you will not waste time converting data, and the process itself will be faster.
2. Use parallel processing
Thanks to the automation of ETL processes, you will be able to carry out extract, transform, and load processing in parallel, in other words, you can perform several simultaneous iterations. This will increase the speed of working with information and minimize the time to payback. The limit to simultaneous iterations will be put only by your own infrastructure.
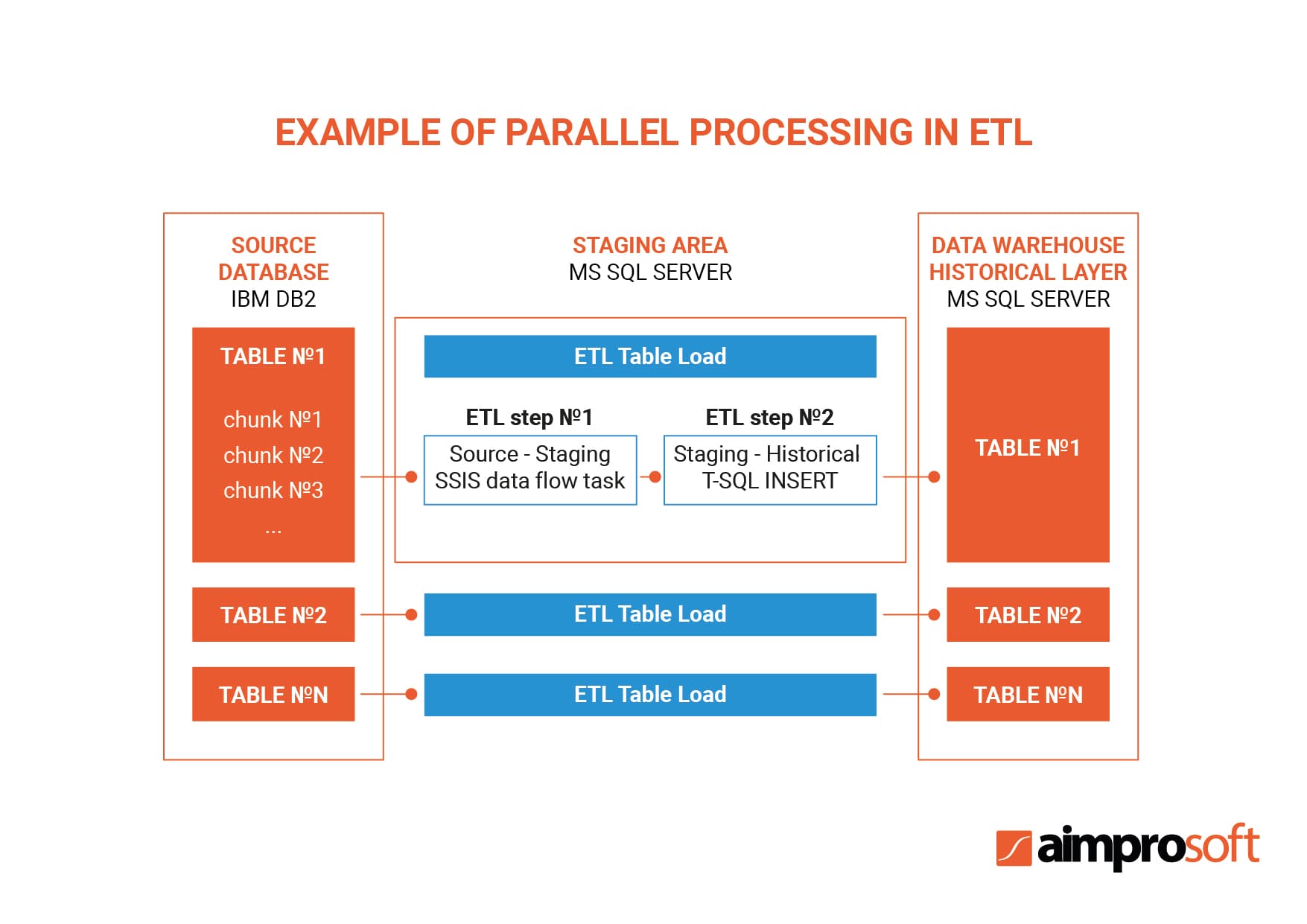
3. Cache data
Data caching means storing used data in a place with quick access, such as a disk or internal memory. If you cache the information in advance, you can boost the entire ETL process. However, keep in mind that this will require a lot of RAM and free space. In addition, the cache function is important for supporting the above-mentioned parallel processing and parallel data caching.
4. Perform table maintenance regularly
The tables need to be maintained and optimized because the smaller they are, the easier and faster ETL processes will be. To speed up your ETL pipelines performance, it is often enough to split large tables into smaller ones.
5. Error handling
The error handling mechanism is critical for ETL processes. It would be best if you make sure this mechanism captures the name of the project and task, as well as the error number and description. The monitoring page will contain all the necessary information about task progress. Therefore, when an error at any stage leads to the entire task’s interruption, it will be possible to fix it by analyzing the monitoring page quickly. We recommend that you log all errors in a separate file, but pay special attention to those that affect your business logic.
6. Monitor daily ETL processes
Monitoring ETL project jobs is the final touch to ascertain the quality of the solution. In most cases, to monitor ETL processes, it is enough to conduct the data validation and check its flow between the two databases. To achieve the proper monitoring of the entire system, we also recommend:
- monitor external jobs delivering data, as it comes from outside;
- it makes sense to control the execution of ETL jobs, namely, to track time spent on them;
- analyze your architecture to identify potential threats and problems in the future;
- track standard database metrics like response time, connectivity, etc.
Let’s look at how we can apply best practices when developing ETL processes and go through its main stages.
4 steps to build an ETL process
1. Copy raw data
Any software project begins with thinking through the details of the system and creating design patterns. The ETL development process is no exception. In most cases, we recommend using batch processing due to its speed and popularity, which gives an informational advantage when some issues arise. Follow these tips before the transformation stage for several reasons:
- To get permissions, you should copy the raw data, as you will not be able to control the source system during transitions between executions.
- Usually, the original system will differ in use from the system you are developing. Performing the redundant steps when extracting records can have an adverse effect on the source system, affecting the end-users.
- Having raw data at your disposal will help speed up the process of finding and solving problems. As the data moves, debugging becomes noticeably more difficult.
- Local raw data is an excellent mechanism for auditing and testing throughout the ETL process.
2. Filter the data
The next step is to filter and fix bad data. It is inaccurate records that will become the main problem at this stage, which you need to solve by optimizing information. We advise you to accompany the bad data in the source documents with the “bad record” or “bad reason” field flag for convenient classification and evaluation of incorrect records from future processing. Filtering will enable you to reduce the result set to the last month of data or ignore columns with null.
3. Transform the data
This step is the most difficult in the ETL development process. The purpose of transformations is to translate data into a warehouse form. We advise you to perform the transformation in stages: first, add keys to the data, then add the calculated columns, and finally combine them to create aggregates. With aggregates’ help, you can interact with information in every possible way: sum, average, find the desired value, and group by columns.
This process will help you keep a logical encapsulation of each step and add “what and why” comments. The combination of multiple transforms can vary depending on the number of steps, processing time, and other factors. The main thing is that you do not allow them to be significantly complicated.
4. Loading data into a warehouse
After transformation, your data should be ready to get loaded into the data warehouse. Before downloading, you will have to decide on its frequency, whether the information will be downloaded once a week or a month. This will affect the work of the data warehouse, as the server will slow down during the loading process, while the data may change. You can deal with its changes by updating existing records with the latest information from data sources or keeping an audit trail of changes.
Our use case
We built the ETL process while working on a project for one of our American customers. The client asked us to create a software product for processing data on various organizations in New York, which included government and private institutions. This directory provided information about the services of these organizations, their addresses, contacts, etc.
Since we dealt with several data sources, we needed to collect information in one centralized place, in other words, develop an ETL process. To solve this problem, our development team analyzed each source’s data formats and wrote an entire program for pulling the data into a temporary base, where it transformed into a standard format.
When working with massive information, our ETL developers found a lot of duplicate records to deal with. We carried out data deduplication with the help of a Java-based solution Duke. The main challenge in performing the ETL process was data testing. It took a lot of time to conduct manual and unit tests for the engine to make it work properly.
As a result, we successfully completed the ETL process, which increased productivity in working with information by 36% and created a consolidated database on the basis of which a complete digital guide for New York was built.
Conclusion
We hope that the observation of the topic has helped you set things straight and answered your most burning questions on how to build an ETL. If you are interested in the peculiarities of the ETL software development and its implementation for your infrastructure, contact us, as we have all the necessary expertise for consulting and performing this task.
Frequently Asked Questions
What is the practical use of the ETL process?
The ETL process allows for analysis of diverse data, no matter how many different sources and formats it comes from.
How to create an ETL process?
The ETL process’ name already contains the encoded answer: first, extract and copy the data, then filter and transform it, and finally load the received data into the data warehouse. That’s how you perform the ETL process in short. However, to build an effective operation of this process, you should follow some specific practices, which you may find in the previous sections of our article “Best practices” and “4 Steps to Build an ETL process.”
How difficult is it to develop an ETL solution?
The difficulty level depends entirely on the variety of supported processing algorithms and the data transformation scale. A simple ETL system can be created in a few months. Developing ETL processes for an enterprise can take years of work as a flexible system will support a ton of processing options.
Why should you use ETL development tools?
ETL development tools greatly simplify the ETL development process and save you time and money, since it may take years to create a flexible system for enterprises with a lot of processing options.
ETL or ELT — what is better for your situation?
ETL design and development stands as a suitable option for small and medium-sized companies being an inexpensive solution with effective information analysis. Due to its cloud nature, ELT requires more money, but is much better suited to big data organizations, offering a fast transformation and loading process.
What is the processing speed and storage limit?
If you have cloud storage, then it is unlimited. If you have physical storage, then the size will entirely depend on your financial capacity and how much equipment you can provide. The processing speed depends on two aspects: the speed of the transformation process and the equipment’s capacity.


